

CockroachDB comes with new easy-to-use SQL syntax for configuring a database across multiple regions. One of these SQL features is to declare a table to have the locality REGIONAL BY ROW, allowing developers to place individual rows of a table in a specific region whilst maintaining the facade of a single SQL table, for example:
CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
username STRING NOT NULL UNIQUE
) LOCALITY REGIONAL BY ROW
;
With this extra piece of syntax during CREATE TABLE, we’ve made row-level data homing simple!
In this blog post, we’ll explore the motivations behind the REGIONAL BY ROW abstraction, take a deeper dive into the abstraction itself, and look behind the scenes to understand how REGIONAL BY ROW works under the covers. We also have a hands-on demo for you to try out at the end, so you can play around with a toy multi-region cluster yourself!
Motivation: Why build REGIONAL BY ROW for data homing?
Let’s say we have a company looking to set up a global presence. With an existing user base in the US, the company is looking to expand to the UK and Australia. They can scale their application to run in multiple regions, but if their database is only located in a single region in the US, users in the UK and Australia pay a heavy latency penalty in each database round trip.

[Image 1: Australian and British users talking to a database in the US pay a heavy latency penalty, but US users have no issue (latency pulled from wondernetwork.com).]
For certain tables, a logical pattern would be to store a user’s data as close to the user as possible. For example, if we sharded our database out onto regions US, Europe and Australia, an Australian user would only need to lookup data in the Australian region.

[Image 2: every user talks to the database “closest to them”, providing a similar low-latency experience wherever they are.]
However, when a user travels, the data store closest to them may not have their row, so we would need to check if their data exists in a different region. If the application implements this using manual sharding, it would need to round trip to the local database as well as the remote database to make this designation. Ideally, the database layer would know about this and perform the fetch in another region on the user’s behalf.

[Image 3: if a user has data that is in a different region than the gateway, the database should fetch the requisite data from the correct region.]
If you’ve ever tried handling multiple regions by manually sharding a database such as MySQL or PostgreSQL, you will be familiar with the pain it would be to do this; coordinating cross-shard transactions, maintaining consistency, and dealing with faults are difficult (if not impossible) to handle correctly in the application layer as the database layer would not do this for you. We should expect a declarative language like SQL to know how to do this under the covers.
CockroachDB does just that; it provides a SQL syntax hiding the complexity of deploying a table partitioned at the row level. In other words, a simple query such as INSERT INTO users (username) VALUES ('krudd07') should automatically insert ‘krudd07’ into the region nearest the user, without the developer having to write complex routing rules of where that data should live. Furthermore, a query such as SELECT * FROM users WHERE id = 'some-uuid' should automatically return the desired row in the most efficient way possible, without the user needing to specify in which region ‘some-uuid’ is located. All operations involving local data should be low-latency.
In other words, CockroachDB is all about making data easy!
How to achieve row-level data homing before v21.1
It was possible to set up CockroachDB to achieve some of the goals mentioned above prior to v21.1, but it was not necessarily easy. If you’re curious, keep reading this section - or feel free to skip ahead!
Let’s assume we want this behaviour for a user table, with every user having a unique username. A basic table with no multi-region capabilities may look like the following:
CREATE TABLE users (
region STRING NOT NULL,
id UUID NOT NULL DEFAULT gen_random_uuid(),
username STRING NOT NULL,
PRIMARY KEY (region, id),
UNIQUE INDEX uniq_usernames_key (region, username) PARTITION BY LIST (region) (
PARTITION "us-east1" VALUES IN (('us-east1')),
PARTITION "europe-west1" VALUES IN (('europe-west1')),
PARTITION "australia-southeast1" VALUES IN (('australia-southeast1'))
)
) PARTITION BY LIST (region) (
PARTITION "us-east1" VALUES IN (('us-east1')),
PARTITION "europe-west1" VALUES IN (('europe-west1')),
PARTITION "australia-southeast1" VALUES IN (('australia-southeast1'
))
);
To turn this into a row level multi-region table in CockroachDB, we will need to partition the data by region. This involves creating a region column and making the region column a prefix of the PRIMARY KEY and UNIQUE INDEX (more on why we need to do this later!):
CREATE TABLE users (
region STRING NOT NULL,
id UUID NOT NULL DEFAULT gen_random_uuid(),
username STRING NOT NULL,
PRIMARY KEY (region, id),
UNIQUE INDEX uniq_usernames_key (region, username) PARTITION BY LIST (region) (
PARTITION "us-east1" VALUES IN (('us-east1')),
PARTITION "europe-west1" VALUES IN (('europe-west1')),
PARTITION "australia-southeast1" VALUES IN (('australia-southeast1'))
)
) PARTITION BY LIST (region) (
PARTITION "us-east1" VALUES IN (('us-east1')),
PARTITION "europe-west1" VALUES IN (('europe-west1')),
PARTITION "australia-southeast1" VALUES IN (('australia-southeast1'
))
);
We are then able to define rules for where these partitions should live:
ALTER PARTITION "us-east1" OF INDEX users@primary
CONFIGURE ZONE USING constraints='[+region=us-east1]';
ALTER PARTITION "europe-west1" OF INDEX users@primary
CONFIGURE ZONE USING constraints='[+region=europe-west1]';
ALTER PARTITION "australia-southeast1" OF INDEX users@primary
CONFIGURE ZONE USING constraints='[+region=australia-southeast1]';
ALTER PARTITION "us-east1" OF INDEX users@uniq_usernames_key
CONFIGURE ZONE USING constraints='[+region=us-east1]';
ALTER PARTITION "europe-west1" OF INDEX users@uniq_usernames_key
CONFIGURE ZONE USING constraints='[+region=europe-west1]';
ALTER PARTITION "australia-southeast1" OF INDEX users@uniq_usernames_key
CONFIGURE ZONE USING constraints='[+region=australia-southeast1]'
;
And now we have a table that allows us to control where rows go to at a row level and is accessible and usable with the existing PostgreSQL-compatible syntax. We can insert rows into specific regions using INSERT INTO users (region, username) VALUES ('australia-southeast1', 'krudd07'), and access the rows directly from the correct region using SELECT * FROM users WHERE region = 'australia-southeast1' AND id ='some-uuid'
However, there are two big gotchas with this approach:
The application needs to change to accommodate the new region column.
The
regionmust be specified duringINSERTsince there is no way to specify aDEFAULTfor the local region. This is another extra step for the developer, who has to actively make a decision on where to insert every single row.You are forced to abandon a purely logical
PRIMARY KEYto use a compoundPRIMARY KEYinstead. Selecting byPRIMARY KEYrequires also selecting byregionto avoid visiting every region. Ideally, you would not have to specifyWHERE region = 'australia-southeast1'to make this faster. This is particularly arduous for developers when migrating their applications to become multi-region.
It is not possible to maintain the same semantics without compromising on performance or compliance.
The
UNIQUE INDEXis now(region, username), which means that global uniqueness is no longer guaranteed onusername;usernameis only guaranteed to be unique per region.If we want to guarantee global uniqueness on
username, we would need to make the index unpartitioned. This would cause many index entries to be located in a different region than their corresponding primary index row, resulting in frequent cross-region transactions and high latencies. This would also be a non-starter for organizations requiring data domiciling, since users’ data may reside in multiple regions.To avoid cross-region latencies when using the unpartitioned
UNIQUE INDEX, we could use the Duplicate Indexes topology pattern. However, this pattern requires replicating index data in every region, which increases write amplification and write latency. It is also incompatible with data domiciling. Furthermore, it requires effort from the DBA to keep all duplicated indexes in sync whenever there are changes to the schema or partitions.
So far, we’ve made some multi-region configurations possible. Developers are able to spread their data across regions whilst maintaining the semantics of a single table. But we have not necessarily made things easy. So we decided to make this better!
What we built: REGIONAL BY ROW for data homing
In line with simplifying the multi-region experience in v21.1, we’ve implemented new declarative syntax with functionality underneath that addresses all the problems mentioned above.
Specifying LOCALITY REGIONAL BY ROW does a lot of work under the covers to take away the burden of partitioning a multi-region database underneath.
If we look at the table we created using SHOW CREATE TABLE, we will notice an implicitly created hidden column underneath named crdb_region, which is used to specify where the row should be domiciled:
demo@127.0.0.1:26257/db> SHOW CREATE TABLE users;
table_name | create_statement
-------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------
users | CREATE TABLE public.users (
| id UUID NOT NULL DEFAULT gen_random_uuid(),
| username STRING NOT NULL,
| crdb_region public.crdb_internal_region NOT VISIBLE NOT NULL DEFAULT default_to_database_primary_region(gateway_region())::public.crdb_internal_region,
| CONSTRAINT "primary" PRIMARY KEY (id ASC),
| UNIQUE INDEX users_username_key (username ASC),
| FAMILY "primary" (id, username, crdb_region)
| ) LOCALITY REGIONAL BY ROW
(1 row
)
The crdb_region column has the type crdb_internal_region, which is an enum with the regions defined on our database as the set of possible values. By default, the column is populated as the gateway_region(), which is the region in which the database was accessed, but defaulting to the PRIMARY REGION if we do not have the region defined on the database. In our example database above, if we insert into the database from asia-east1, we would populate that row as our PRIMARY REGION us-east1. Finally, the column is marked NOT VISIBLE, so it does not show up on SELECT * style queries.
In essence, we can use this table the exact same way as if we would if we were interacting with a regular PostgreSQL, single sharded table. However, there is some magic under the covers:
On performing inserts, using
INSERT (username) INTO users VALUES ('krudd07')would insert the row with thecrdb_regionset to the region we were executing from - let’s sayaustralia-southeast1. This will automatically home the data to a data store in that region.When performing selects referencing the
PRIMARY KEYor theUNIQUE INDEX, we will automatically look up from thegateway_region()first before fanning out to other regions to check for the existence of that row - matching the behaviour described in “motivation” above. Since we are likely going to find the data for a given user from a server in the same region, this will most likely hit the data store closest to us and enable a response with low latency for the user.Finally, uniqueness is still guaranteed on the
PRIMARY KEYandUNIQUE INDEX. This is enforced with automatic, additional checks any time rows are inserted or updated, avoiding the need for any duplicate indexes.
We believe this is a powerful feature for developers to initiate a low-latency multi-region cluster. With a few simple keywords, everything is taken care of underneath the covers.
How REGIONAL BY ROW works underneath the hood
We discussed a lot of magic behind the LOCALITY REGIONAL BY ROW above, let’s discuss how it all works underneath.
Background
Ranges
All SQL operations in CockroachDB are translated to key-value (KV) operations in our storage engine Pebble. In essence, a PRIMARY KEY serves as the key and the value is the rest of the row. Keys are stored in sorted order.

Furthermore, each secondary index (such as our UNIQUE INDEX) can be construed as a key which maps back to the PRIMARY KEY.
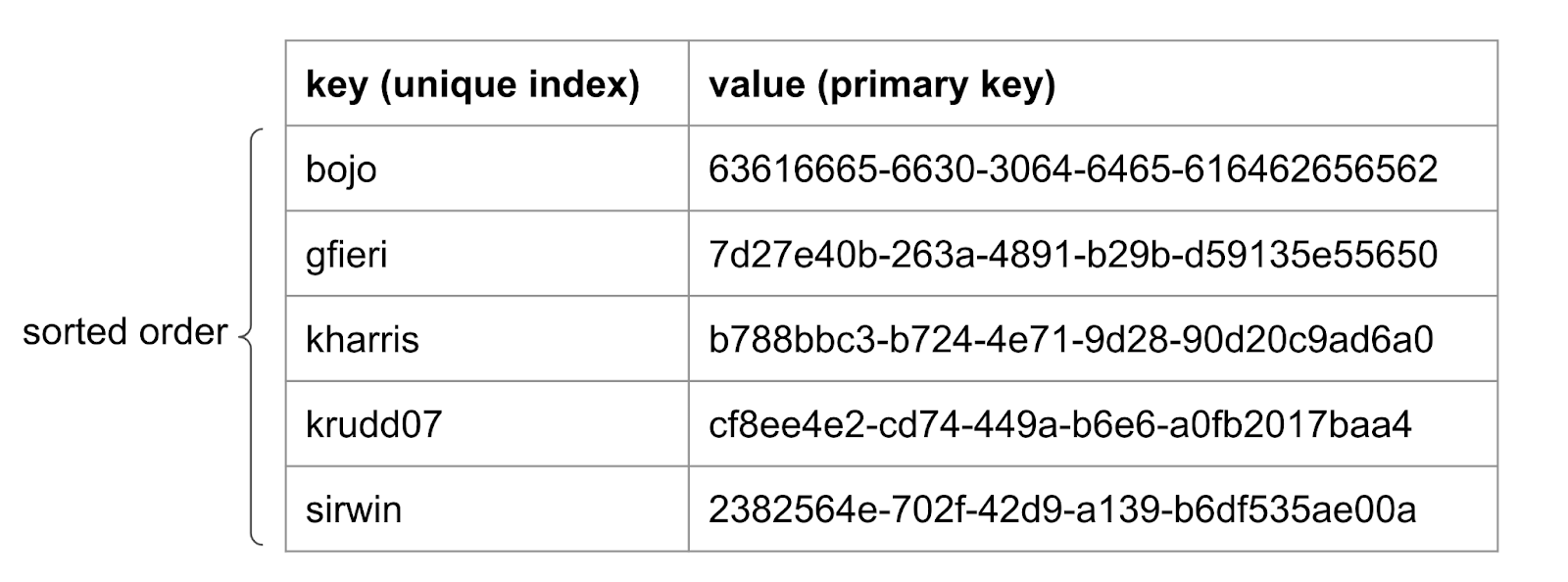
This KV layer is split into chunks, known as “ranges”. Ranges can be split or merged, but rows are always stored in sorted order within the same range. For example, we can split our table into three ranges:

Partitions and Zone Configurations
Partitions are a contiguous set of keys from the KV store which can form multiple ranges.
We can then apply zone configurations for each partition, which specify where these ranges should live.
In order to partition a table prior to v21.1, partitions require the partitioning columns to be a prefix of the PRIMARY KEY. This is so that we can split ranges as a contiguous slice, making it easier to distribute. Using our example above, we can partition by the region of the given user:

Here-in lies the problem mentioned above! As we need the region name as a prefix of the PRIMARY KEY to partition the table, developers need to be aware of the concept and write their SQL queries accordingly. In this case, doing a query such as SELECT * FROM user WHERE id = '2382564e-702f-42d9-a139-b6df535ae00a' would not be a direct lookup. Since we did not specify the region which is part of the PRIMARY KEY, we would have to visit every region.
REGIONAL BY ROW under the covers
REGIONAL BY ROW resolves the issues raised above by introducing two features - implicit partitioning and locality optimized search.
Implicit Partitioning
In v21.1, we introduced the concept of implicit partitioning, where each row is still partitioned by some set of columns but the partitioning is hidden from the user. Essentially, we are allowing developers to partition by any column without requiring the column to be a strict prefix of the column. Underneath, we still store this as a prefix of each key. For REGIONAL BY ROW, the crdb_region column is the implicit partitioning.

Here, the uniqueness of a PRIMARY KEY is only dependent on the column id. This means the range activity underneath remains “invisible” to the developer. The table looks and behaves exactly as it would even if it was on a single-node PostgreSQL instance.
Similarly, all indexes (including unique indexes) defined on the table are implicitly partitioned with crdb_region as the prefix:

(how a UNIQUE INDEX would look in KV using REGIONAL BY ROW split by ranges)
CockroachDB also guarantees that implicitly partitioned unique indexes will enforce uniqueness on the columns explicitly included in the index definition. In this example, CockroachDB guarantees that username is globally unique.
Enforcing Uniqueness with Implicit Partitioning
To guarantee uniqueness in this case, we needed to add some new functionality to the SQL query optimizer as part of the 21.1 release. Unique indexes can only directly enforce uniqueness on all columns we are indexing on, including partitioning columns. Without the new functionality, the UNIQUE INDEX in the REGIONAL BY ROW table would only be able to enforce uniqueness for username per region. Therefore, the database needs to do additional work to enforce global uniqueness. This “additional work” is in the form of “uniqueness checks” that the optimizer adds as part of mutation queries. You can see the checks if you run EXPLAIN on any mutation query affecting the table.
For the following insert query, the optimizer has added a “constraint-check” post query to check the uniqueness of username. This is a query that runs right after the mutation as part of the same transaction, and will cause the transaction to fail if it returns any rows. There is no unique check needed for id since the probability of collision with gen_random_uuid() is vanishingly small (if you still want the checks anyway, we provide a cluster setting, sql.optimizer.uniqueness_checks_for_gen_random_uuid.enabled, to enable them).
demo@127.0.0.1:26257/db> EXPLAIN INSERT INTO users (username) VALUES ('krudd07');
info
-----------------------------------------------------------------------------------------
distribution: local
vectorized: true
• root
│
├── • insert
│ │ into: users(id, username, crdb_region)
│ │
│ └── • buffer
│ │ label: buffer 1
│ │
│ └── • values
│ size: 4 columns, 1 row
│
└── • constraint-check
│
└── • error if rows
│
└── • lookup join (semi)
│ table: users@users_username_key
│ equality: (lookup_join_const_col_@12, column1) = (crdb_region,username)
│ equality cols are key
│ pred: (column7 != id) OR (column8 != crdb_region)
│
└── • cross join
│ estimated row count: 3
│
├── • values
│ size: 1 column, 3 rows
│
└── • scan buffer
label: buffer 1
(32 rows
)
These uniqueness checks work by checking whether the value inserted for the unique column already exists in any other region. As a result, executing the query requires visiting every region in the database, thus incurring cross-region latencies. Therefore, the optimizer tries to avoid adding these checks whenever it is safe to do so. You can also eliminate the need for these checks entirely in a few ways:
Use a UUID for the unique column with
DEFAULT gen_random_uuid(). As mentioned above, the optimizer will not check for uniqueness when theDEFAULTis used unlesssql.optimizer.uniqueness_checks_for_gen_random_uuid.enabledis true.If you only need to guarantee uniqueness for a column per region, you can explicitly include
crdb_regionin theUNIQUE INDEXdefinition. For example,UNIQUE (crdb_region, col)guarantees that col is unique per region, and does not require additional checks.If you already know how to partition your table with the existing primary key, you can define
crdb_regionas a computed column. For example, consider the table below. In this case, uniqueness checks are not needed to guarantee the uniqueness of id:
CREATE TABLE users (
id INT PRIMARY KEY,
user_data STRING,
crdb_region public.crdb_internal_region NOT VISIBLE NOT NULL AS (CASE WHEN id % 2 = 0 THEN 'us-east1' ELSE 'australia-southeast1' END) STORED
) LOCALITY REGIONAL BY ROW
;
Although enforcing global uniqueness can increase the latency of some INSERTs and UPDATEs, it allows CockroachDB to maintain the integrity of global UNIQUE constraints while keeping all data for a given row in a single region. It also has a big benefit: servicing a query such as SELECT * FROM users WHERE id = 'some-userid' can be just as fast as it would be in a single-region deployment. How does this work, you may ask? The answer is an optimization we call “Locality Optimized Search”.
Locality Optimized Search
Locality Optimized Search is an optimization that is possible when a user is searching for a row that is known to be unique, but its specific location is unknown. For example, SELECT * FROM users WHERE id = 'some-userid' does not specify the region where 'some-userid' is located, but it is guaranteed to return at most one row since id is known to be unique. CockroachDB takes advantage of the uniqueness of id by searching for the row in the local region first. If the row is found, there is no need to fan out to remote regions, since no more rows will be returned. Assuming data is generally accessed from the same region where it was originally inserted, this strategy can avoid visiting remote nodes and result in low latency for many queries.
Locality Optimized Search is planned by the optimizer as a limited UNION ALL, where the left side of the UNION ALL scans the local nodes, and the right side scans the remote nodes. If the limit is reached by the left side, the UNION ALL will short-circuit and avoid executing the right side. We can see an example of locality optimized search by running EXPLAIN on a sample query:
demo@127.0.0.1:26257/db> EXPLAIN SELECT * FROM users WHERE username = 'krudd07';
info
------------------------------------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• union all
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ estimated row count: 1 (0.10% of the table; stats collected 27 seconds ago)
│ table: users@users_username_key
│ spans: [/'australia-southeast1'/'krudd07' - /'australia-southeast1'/'krudd07']
│
└── • scan
estimated row count: 1 (0.10% of the table; stats collected 27 seconds ago)
table: users@users_username_key
spans: [/'europe-west1'/'krudd07' - /'europe-west1'/'krudd07'] [/'us-east1'/'krudd07' - /'us-east1'/'krudd07']
(16 rows
)
Tutorial: How to simulate a database running in multiple regions
You can simulate running a multi-region cluster with cockroach demo. If you download the latest binary, you can recreate the examples from this blog post as follows.
We will first start a node with --nodes 9, which sets up a 9-node cluster with 3 nodes in europe-west1, 3 nodes in us-east1 and 3 nodes in us-west1. The --global flag also simulates latencies between regions, mimicking a real world cluster.
$ cockroach demo --no-example-database --nodes 9 --global
Now we can look at the regions in the cluster. Note that cockroach demo only supports us-east1, us-west1 and europe-west1 for demo, so we will label all our australia-southeast1 users as us-west1.
demo@127.0.0.1:26257/defaultdb> SHOW REGIONS;
region | zones | database_names | primary_region_of
---------------+---------+----------------+--------------------
europe-west1 | {b,c,d} | {} | {}
us-east1 | {b,c,d} | {} | {}
us-west1 | {a,b,c} | {} | {}
(3 rows
)
We can check which region the node we are connected to is using gateway_region(). When using --global, we are connected to ‘us-east1’ by default.
demo@127.0.0.1:26257/defaultdb> SELECT gateway_region();
gateway_region
------------------
us-east1
(1 row)
Time: 1ms total (execution 0ms / network 1
ms)
We can then create a database which can have data in all the regions in the cluster:
demo@127.0.0.1:26257/defaultdb> CREATE DATABASE db PRIMARY REGION "us-east1" REGIONS "us-west1", "europe-west1";
CREATE DATABASE
Time: 1.691s total (execution 1.691s / network 0.000
s)
Now we can create a REGIONAL BY ROW table in the database:
demo@127.0.0.1:26257/defaultdb> USE db;
SET
Time: 12ms total (execution 12ms / network 0ms)
demo@127.0.0.1:26257/db> CREATE TABLE users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
username STRING NOT NULL UNIQUE
) LOCALITY REGIONAL BY ROW;
CREATE TABLE
Time: 895ms total (execution 416ms / network 479
ms)
Using SHOW CREATE TABLE, we can see the CREATE TABLE command implicitly introduced the implicit crdb_region column.
demo@127.0.0.1:26257/db> SELECT create_statement FROM [SHOW CREATE TABLE users];
create_statement
---------------------------------------------------------------------------------------------------------------------------------------------------------------
CREATE TABLE public.users (
id UUID NOT NULL DEFAULT gen_random_uuid(),
username STRING NOT NULL,
crdb_region public.crdb_internal_region NOT VISIBLE NOT NULL DEFAULT default_to_database_primary_region(gateway_region())::public.crdb_internal_region,
CONSTRAINT "primary" PRIMARY KEY (id ASC),
UNIQUE INDEX users_username_key (username ASC),
FAMILY "primary" (id, username, crdb_region)
) LOCALITY REGIONAL BY ROW
(1 row)
Time: 2.056s total (execution 2.055s / network 0.000
s)
We are able to observe underneath that the table PRIMARY KEY and UNIQUE INDEX have implicit partitions:
demo@127.0.0.1:26257/db> SELECT partition_name, index_name, zone_config FROM [SHOW PARTITIONS FROM TABLE users];
partition_name | index_name | zone_config
-----------------+--------------------------+-------------------------------------------------
europe-west1 | users@primary | num_voters = 3,
| | voter_constraints = '[+region=europe-west1]',
| | lease_preferences = '[[+region=europe-west1]]'
europe-west1 | users@users_username_key | num_voters = 3,
| | voter_constraints = '[+region=europe-west1]',
| | lease_preferences = '[[+region=europe-west1]]'
us-east1 | users@primary | num_voters = 3,
| | voter_constraints = '[+region=us-east1]',
| | lease_preferences = '[[+region=us-east1]]'
us-east1 | users@users_username_key | num_voters = 3,
| | voter_constraints = '[+region=us-east1]',
| | lease_preferences = '[[+region=us-east1]]'
us-west1 | users@primary | num_voters = 3,
| | voter_constraints = '[+region=us-west1]',
| | lease_preferences = '[[+region=us-west1]]'
us-west1 | users@users_username_key | num_voters = 3,
| | voter_constraints = '[+region=us-west1]',
| | lease_preferences = '[[+region=us-west1]]'
(6 rows)
Time: 5.319s total (execution 5.319s / network 0.000
s)
With an implicit crdb_region column on each index:
demo@127.0.0.1:26257/db> SELECT index_name, seq_in_index, column_name, implicit FROM [SHOW INDEXES FROM users];
index_name | seq_in_index | column_name | implicit
---------------------+--------------+-------------+-----------
primary | 1 | crdb_region | true
primary | 2 | id | false
users_username_key | 1 | crdb_region | true
users_username_key | 2 | username | false
users_username_key | 3 | id | true
(5 rows)
Time: 1.942s total (execution 1.942s / network 0.001
s)
Looking at the EXPLAIN plan for inserting rows into users, we can see that the optimizer adds a constraint check to ensure that the username column remains globally unique. Note we first run ANALYZE to ensure the statistics are up to date (this is done automatically in the background in normal operation, but we are doing it here for deterministic results).
demo@127.0.0.1:26257/db> ANALYZE users;
ANALYZE
Time: 3.857s total (execution 3.857s / network 0.000s)
demo@127.0.0.1:26257/db> EXPLAIN INSERT INTO users (crdb_region, username) VALUES
('us-west1', 'sirwin'),
('us-west1', 'krudd07'),
('europe-west1', 'bojo'),
('us-east1', 'gfieri'),
('us-east1', 'kharris');
info
------------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• root
│
├── • insert
│ │ into: users(id, username, crdb_region)
│ │
│ └── • buffer
│ │ label: buffer 1
│ │
│ └── • render
│ │ estimated row count: 5
│ │
│ └── • values
│ size: 2 columns, 5 rows
│
└── • constraint-check
│
└── • error if rows
│
└── • hash join (semi)
│ estimated row count: 2
│ equality: (column2) = (username)
│ pred: (column8 != id) OR (column1 != crdb_region)
│
├── • scan buffer
│ label: buffer 1
│
└── • scan
estimated row count: 5 (100% of the table; stats collected 54 seconds ago)
table: users@primary
spans: FULL SCAN
(33 rows)
Time: 4ms total (execution 3ms / network 1
ms)
Now let’s perform the insertion.
demo@127.0.0.1:26257/db> INSERT INTO users (crdb_region, username) VALUES
('us-west1', 'sirwin'),
('us-west1', 'krudd07'),
('europe-west1', 'bojo'),
('us-east1', 'gfieri'),
('us-east1', 'kharris');
INSERT 5
Time: 283ms total (execution 283ms / network 0
ms)
We can also insert rows without specifying the region, and they will automatically be inserted into the local region us-east1.
demo@127.0.0.1:26257/db> INSERT INTO users (username) VALUES ('skimball') RETURNING crdb_region;
crdb_region
---------------
us-east1
(1 row)
Time: 172ms total (execution 172ms / network 0
ms)
We can use EXPLAIN to see how the optimizer plans a locality optimized partitioned index scan of the UNIQUE INDEX on username (first running ANALYZE to ensure the statistics are refreshed).
demo@127.0.0.1:26257/db> ANALYZE users;
ANALYZE
Time: 4.054s total (execution 4.054s / network 0.000s)
demo@127.0.0.1:26257/db> EXPLAIN SELECT * FROM users WHERE username = 'kharris';
info
------------------------------------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• union all
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ estimated row count: 1 (19% of the table; stats collected 4 minutes ago)
│ table: users@users_username_key
│ spans: [/'us-east1'/'kharris' - /'us-east1'/'kharris']
│
└── • scan
estimated row count: 1 (19% of the table; stats collected 4 minutes ago)
table: users@users_username_key
spans: [/'europe-west1'/'kharris' - /'europe-west1'/'kharris'] [/'us-west1'/'kharris' - /'us-west1'/'kharris']
(16 rows)
Time: 4ms total (execution 4ms / network 0
ms)
Running this query is extremely fast (1 ms in our instance), since kharris is located in us-east1, the default local region of the demo cluster. Because the data was found locally, there was no need to search remote nodes.
demo@127.0.0.1:26257/db> SELECT * FROM users WHERE username = 'kharris';
id | username
---------------------------------------+-----------
787db177-9167-4f1c-9e5e-813a18a985b8 | kharris
(1 row)
Time: 1ms total (execution 1ms / network 0
ms)
However, running the same query with sirwin is a bit slower (73 ms in our instance) as sirwin is located in the remote region us-west1.
demo@127.0.0.1:26257/db> SELECT * FROM users WHERE username = 'sirwin';
id | username
---------------------------------------+-----------
b2694fbd-09c2-43d2-acf7-98a9e8367fa4 | sirwin
(1 row)
Time: 73ms total (execution 73ms / network 0
ms)
We can see from the EXPLAIN ANALYZE that we checked locally in us-east1 first, but this is a negligible latency increase as we are looking within the same region. The DistSQL diagram (the distributed SQL plan visible by opening the URL after Diagram:) shows that less than 1ms was spent in the local lookup.
demo@127.0.0.1:26257/db> EXPLAIN ANALYZE (DISTSQL) SELECT * FROM users WHERE username = 'sirwin';
info
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
planning time: 378µs
execution time: 71ms
distribution: local
vectorized: true
rows read from KV: 1 (58 B)
cumulative time spent in KV: 70ms
maximum memory usage: 20 KiB
network usage: 0 B (0 messages)
• union all
│ cluster nodes: n1
│ actual row count: 1
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ cluster nodes: n1
│ actual row count: 0
│ KV rows read: 0
│ KV bytes read: 0 B
│ estimated row count: 1 (16% of the table; stats collected 6 minutes ago)
│ table: users@users_username_key
│ spans: [/'us-east1'/'sirwin' - /'us-east1'/'sirwin']
│
└── • scan
cluster nodes: n1
actual row count: 1
KV rows read: 1
KV bytes read: 58 B
estimated row count: 1 (16% of the table; stats collected 6 minutes ago)
table: users@users_username_key
spans: [/'europe-west1'/'sirwin' - /'europe-west1'/'sirwin'] [/'us-west1'/'sirwin' - /'us-west1'/'sirwin']
Diagram: https://cockroachdb.github.io/distsqlplan/decode.html#eJykkuFu0zAQx7_zFKf7Mgl5ihMEG5aQKlAQE2Odugk-kGhy42OzaOxgO1qnKo_FC_BkqHZH13VFsH2Jcv_z33f3Oy_Q_5ihwLPyuHx3Ds_h_WT8CXpPzsOXD-WkjP9GtgRvYM9rd63NHjI0VtGJbMmj-Io51gw7Zxvy3rqltIgHjtQcBWeoTdeHpVwzbKwjFAsMOswIBZ7L6YwmJBW5jCNDRUHqWbw2djGK34vbLi6-0w0yPOuk8QKyCkcVZhWmxirc31KyU0ff9Lw0CqRRkIMNV-SQ4bgPAkY5GxXI8ONnCLolAa9etz7FjTWBTNDWrFL8189VytlrD46kEpAnZXoT6FZ6eQhvkeFUhuaKPNg-dMtSy5PRuBbqgWGKVnB8kJeEIh_Y4wDmjwBYVfNDvgVxW12D3Anv4ODwD6N_w8e38fEH6fH79PhOesVOemtovbFOkSO1AaweHuB7YvdtlxWbZI91q0NcKc2p6e-MWaQxn7B9_j_bn5DvrPF0b45dN9cMSV1SguFt7xo6dbaJZVI4jr4oKPIhZYsUHJmYis_zrjl_irn4q_nFhpkP9fDsdwAAAP__NECKOw==
(34 rows)
Time: 72ms total (execution 72ms / network 0
ms)
Opening up the URL after Diagram: gives us a visualised plan which shows that the KV time for the local lookup is 778 microseconds, while the bulk of the time is spent in the remote lookup:

However, if we connect a SQL session to the us-west1 server, we can observe that it is fast to read locally. Note cockroach demo starts SQL ports at 26257, and assigns ports incrementally - so 26257-26259 is us-east1, 26260-26262 is us-west1 and 26263-26265 is europe-west1.
Let’s connect to port 26260 and we can see the gateway region is us-west1:
$ ./cockroach sql --url 'postgres://demo:demo12295@127.0.0.1:26260?sslmode=require'
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: q.
#
# Server version: CockroachDB CCL v21.2.0-alpha.00000000-136-gffc6346eaa-dirty (x86_64-apple-darwin19.6.0, built , go1.15.11) (same version as client)
# Cluster ID: 42ce8535-54a4-4cf0-946c-35c53bcd2007
# Organization: Cockroach Demo
#
# Enter ? for a brief introduction.
#
demo@127.0.0.1:26260/defaultdb> select gateway_region();
gateway_region
------------------
us-west1
(1 row)
Time: 1ms total (execution 0ms / network 0
ms)
Now let’s run the same SELECT on sirwin who was on us-west1:
demo@127.0.0.1:26260/defaultdb> use db;
SET
Time: 0ms total (execution 0ms / network 0ms)
demo@127.0.0.1:26260/db> SELECT crdb_region, * FROM users WHERE username = 'sirwin';
crdb_region | id | username
--------------+--------------------------------------+-----------
us-west1 | acb33f0c-871e-4eb8-a31d-be15659ba803 | sirwin
(1 row)
Time: 1ms total (execution 1ms / network 0
ms)
And we can see that the same query is now fast as us-west1 is a local read.
Row-level data homing has never been easier!
We strive to make it easy to deploy a database across multiple regions with CockroachDB. With our REGIONAL BY ROW abstraction, users can easily create rows homed in the different regions yet accessible using the familiar declarative SQL syntax.
If you’re interested in joining us in making data easy, check out our careers page!


